

Last Updated on: September 23, 2022
Table of Contents
How good are you at data science skills and concepts?
In 2020, Data science is a paradigm everyone is trying to step on for quality upliftment in a career. Reasonable job pay and an opportunity where candidates find the growing path almost exponential has encouraged them to take on Data Science certified programs from various institutes. We present to you a few questions which your interviewer might seriously be expecting from you to know about. They are going to help you understand the concept better and get you interview-ready. Check out these Data Science Python interview questions as well as Python Machine Learning Interview Questions for different levels ranging from entry level to advanced.
Python Interview Questions for Freshers
1. Which programming language would you prefer for text analytics?
Both R and Python can be used, but Python will remain one step ahead because of its versatility, and more user-friendliness.R has got its relevance more into machine learning and statistical analysis. Python has libraries that are easy to handle. One should learn both and use it accordingly to better significance. That is why, When it comes to the data world, Data science and Python course are designed in sync.
2. Why is data cleaning necessary before analysis?

Crude data is unsorted and may contain a lot of impurities that may stack unnecessary memory and may create a hindrance in extracting exact information. To make data glitch-free, we need data cleaning to ensure there is no data redundancy, duplicity, missing values, or statistical outliers. Data cleaning process
Importing data scope -> combining data sets -> structuring missing data -> standardisation -> Normalisation -> De-duplication -> Authentication -> Exporting data scope.
3. What is data sampling?
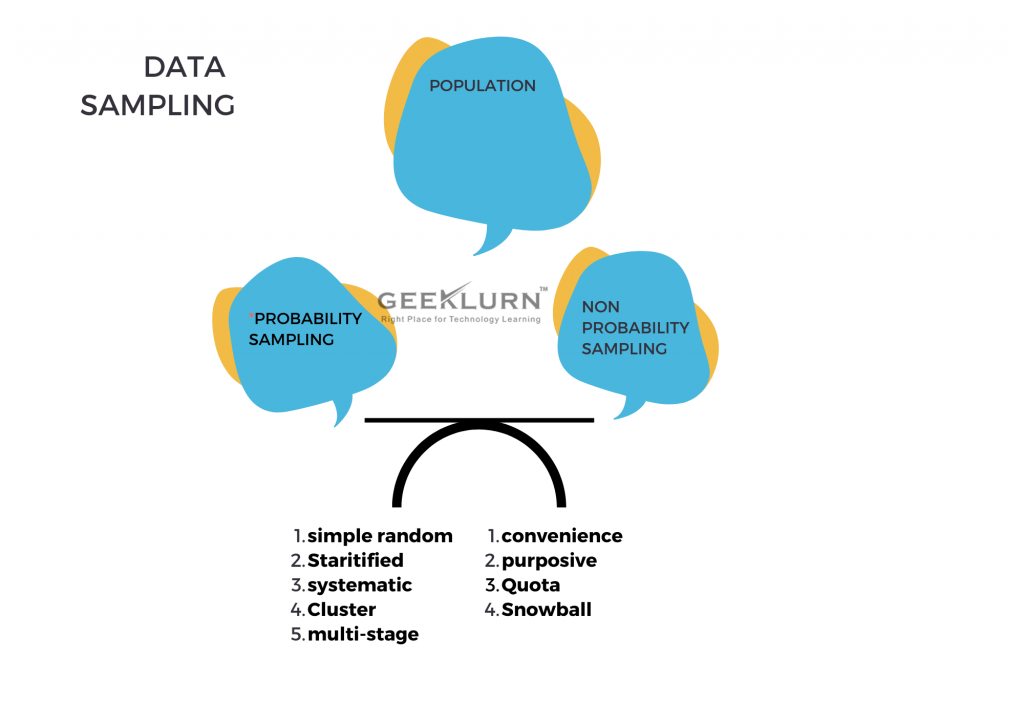
Data sampling is a process where a larger data set is taken, and a statistical analytical technique is used to collect, manipulate, and analyse a subset of data and to find out patterns. Data scientists and Data analysts find it helpful when it gets difficult to work on a large set of data at one time.
4. What is linear regression in Data science?
Linear regression is the stepping stone for data scientists. It is the oldest way to predictive analysis through a machine learning algorithm.
Mathematically,
Y= X1+X2+X3
where it aims to target a predictive variable by finding a linear relationship between the dependent and independent variables.
Y=Dependent/outcome variablealgo
X1,X2,X3= Independent/Predictor value.
5. What is root cause analysis in Data modeling?
To understand the grievance and reason of any data set, which may cause any downgrade to the organisation and address the issue, resolving it is called root cause analysis.
Root cause analysis gets prosecuted through five stages.
Defining the problem, investigating the cause, implementation of logic, ensuring countermeasures, and getting to work on the solution.
6. What are the benefits of using Python?
Python is a general-purpose programming language. Its simple syntax ensures readability. The other advantages stem from the fact that it lends itself to scripting, is open-source & supports third-party packages. Additionally, its high-level data structures along with its dynamic typing & binding are a big pull for developers.
7. What is a dynamically typed language?
Typing refers to type-checking in programming languages. Type checking, in turn can be done at two stages:
Static- Here data types are checked before execution
Dynamic- Data types are checked during execution
Python is a dynamically typed language, where the type-checking is done during execution.
8. Why is PEP 8 important?
This is one of the easy Data Science Python interview questions.
PEP stands for Python Enhancement Proposal. It is a design document that offers information to the Python community, describing new features or processes. PEP8 documents the style guidelines for Python Code. To be able to contribute to the Python open-source community, it is important to follow these guidelines stringently.
9. Name the native data structures in Python. Among them, which is mutable and immutable?
The native data structures in Python are
1. list
2. dictionaries
3. set
4. tuples
5. strings
Among all these lists, set and dictionaries are mutable, rest are not
10. What are the libraries in Python that can be used for data analysis and computation?
The various libraries under python framework are
· Matplotlib
· NumPy
· seaborn
· Pandas
· SciPy
· SciKit
11. What is the difference between long and wide data formats?
This one is a frequently asked Python interview question for freshers.
In a wide format, the data subjects are arranged in a single row, and responses are collected in different columns.
Long format: In a long format, every subject will have data in multiple rows. Each row is dedicated to one single data.
Basic Python Programming Interview Questions
12. What are hash table collisions in data?
In Java, when two different objects have the same hash-code or when two different keys have the same hash code, an ambiguity occurs, which results in intra-interference of data. It is called hash table collisions.
13. What are the different sorting algorithms available in R?
There are two kinds of sorting.
Comparison sorting where the key values are directly compared before ordering and non-comparison sorting where keys get computed first and then ordered.
· Insertion sort
· Bubble sort
· Selection sort
· Shell sort
· Merge sort
· Quicksort
· Heapsort
· Bin sort and radix sort
14. How can you copy objects in Python?
The commands are as below:
Copy.copy () for shallow copy
Copy.deepcopy () for deep copy
However, it is important to remember that all objects in Python cannot be copied using these functions. Dictionaries, for example, have a separate copy method. Similarly, sequences can be copied using “slicing.”
15. What is the difference between tuples and lists in Python?
One of the basic Data Science Python interview questions you might be asked is this one.
While lists are mutable, tuples are immutable. Also tuples need to be used when the sequence is of importance.
16. What is PEP8?
PEP comprises coding guidelines for Python. It enables programmers to write readable code. PEP8 particularly documents the style guidelines for Python code for the Python open-source community to be able to make a contribution.
17. What is “Naive Bayes Algorithm”?
Naive Bayes Algorithm is the machine learning algorithm which involves high dimensional training sets and resolves text classification issues. Spam filtration and sentimental analysis are a few to be named. This algorithm is based on Bayes theorem:
P(A/B) = P(B/A) P(A)/ P(B)
P(A/B) : Posterior
P(B/A): Likelihood
P(A): Prior probability
P(B): Evidence prior probability.
This algorithm is stated as “Naive” because it is based on mere assumptions where the occurrence of features are independent of one another. This algorithm is helpful in data mining as they make the design model fast and give quick predictions.
18. How do you carry out steps in handling a data analytics project?
Data collection phase:
· Inquire about the question.
· Decide to take on w sampling method.
Data descriptive analysis:
· Explore data.
· summarise data samples.
· Work on modeling by finding our missing values.
· Run the model and analyse it.
Data inferential analysis:
· Look out for the statistical significance of the modeled data.
· Do model implementation and analyse the tracked performance.
· Go for periodic analysis.
19. What are exquisite algorithms used by Data scientists?

Various machine learning algorithms for data science are categorised into supervised and unsupervised zones.
20. What is Bayesian estimate?
Posterior= (likelihood*prior)/evidence.
The Bayesian estimate is used to minimise the posterior
value of any lost information or data
21. What is deep learning?
Deep learning is a successor of machine learning where it deals with an algorithm based on brain structure and functionality called artificial neural networks.
Goodfellow and Aaron Courville, define deep learning in terms of the depth of the architecture of the models:
The hierarchy of lessons allows the computer to learn cumbersome concepts by creating them out of simpler ones. If we draw a graph showcasing how these concepts are built on top of each other, the graph is steep, with multilayers. For this reason, we can map this approach to AI deep learning.
Advanced Python Data Science Interview Questions and Answers
22. What is box cox transformation in a regression model?
Box-cox transformation is a data normalisation method invented by statistician George Box and David Cox. It involves a process to determine a suitable exponent value (lambda), which will change the indulged distribution of data to normal distribution.
23. What is the maximum likelihood estimation(MLE)?
In statistics, MLE is a method used to evaluate the parameters of a statistical model given the observation by finding out the parameter value, which may maximise the likelihood of curating the observations that have to occur. The difference between probability and likelihood is, probability relates more to the “occurrence” and likelihood relates more to the “hypothesis.”
24. What is “Boltzman machine”?
This is a method or process that can automatically find patterns in the data by reconstructing the inputs. The purpose of the Boltzman machine is to optimise data solutions altering the weight and quantity. Invented by Geoffry Hilton and Terry Sejnowski, Boltzmann machines are recurring structures consisting of stochastic neurons in binary possibilities, either 1 or 0. The optimisation techniques are based on training and testing algorithms.
25. How MapReduce works?
Mapreduce is a program model used to process huge data parallelly across the Hadoop cluster. Hadoop runs MapReduce in different programming languages like C++, Ruby, Python, Java.
Principle of MapReduce goes through four-phase
• Splitting
• mapping
• shuffling
• reducing
26. How will you use Pandas library to import a CSV file from a URL?
The steps for the same are as follows:
import pandas as pd
Data = pd.read_CV(‘sample_url’)
27. What are universal functions for n-dimensional arrays?
Universal functions refer to those functions that perform mathematical operations on every element of the n-dimensional array. Examples include np.sqrt() and np.exp() which evaluate the square root and exponential of each element of an array respectively.
28. What are the deep learning frameworks?
Deep learning frameworks are the interface to designing deep learning models in more quicker aspects without going deep into the complicated algorithms. some of deep learning frameworks are:
• TensorFlow
• Keras
• Pytorch
• Caffe
• Deeplearning4j
• MXNET
• Chainer
• PaddlePaddle
• MATLAB
29. List a few statistical methods available for a NumPy array
Some of the methods include:
np.means(), np.cumsum(), np.sum(),
30. What do you exactly mean by random forest and decision tree in data science?
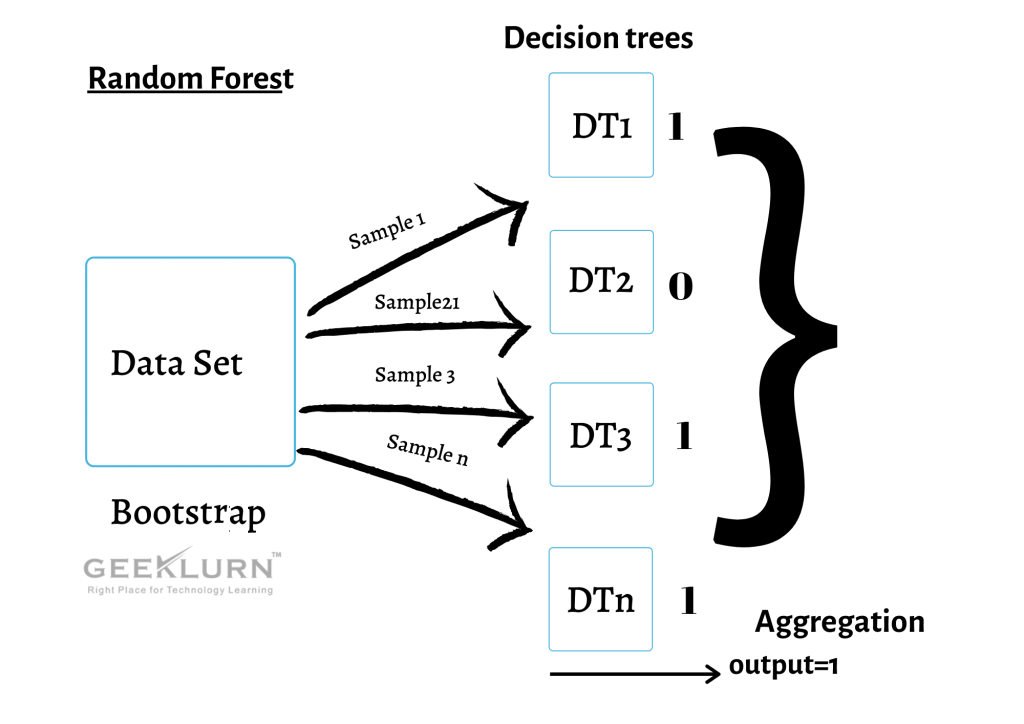
Random forests are also known as Bootstrap aggregation. It is an ensemble technique that uses multiple decision trees to conclude the answer. Basically, the ensemble means combining multiple models, which can be categorised as Bagging and Boosting.
Bagging- Random forest classifier
Boosting- AdaBoost.XgBoost, Gradient.
Process:
A data set is given to a number of decision trees with sample model replacements. Each decision tree will get trained to respective sampling to give an output (0/1). After training is done, different accuracy is calculated across each decision tree. The mean of all accuracy is taken i.e., an average of completely random data. Now determine how many decision trees give the same output. The output which has occurred the maximum no. of times either 0 or 1 is taken as the final result and is called aggregation.These are some Python data science interview questions that will stand you in good stead, depending upon the level at which you are applying.
Monica Swain
Monica is a senior marketing executive. Her skillsets consist of digital marketing and strategy, SEO, marketing analysis and more. She also has her expertise in writing various copies, including web, newsletters, e-books, social media, etc. But, it does not stop here. Her love for writing goes as far as doing poetry connecting science and life.


